DocLifts — A Multi-LLM Development Process
Updated 2026-06-02
What's worth showcasing here is the process, not the product. DocLifts is a small, real, single-user app — but it was built end-to-end as an exercise in coordinating multiple AI tools around a fixed set of written invariants, with a human directing and verifying throughout. It shipped to production and is in daily real use.
The shape of the project
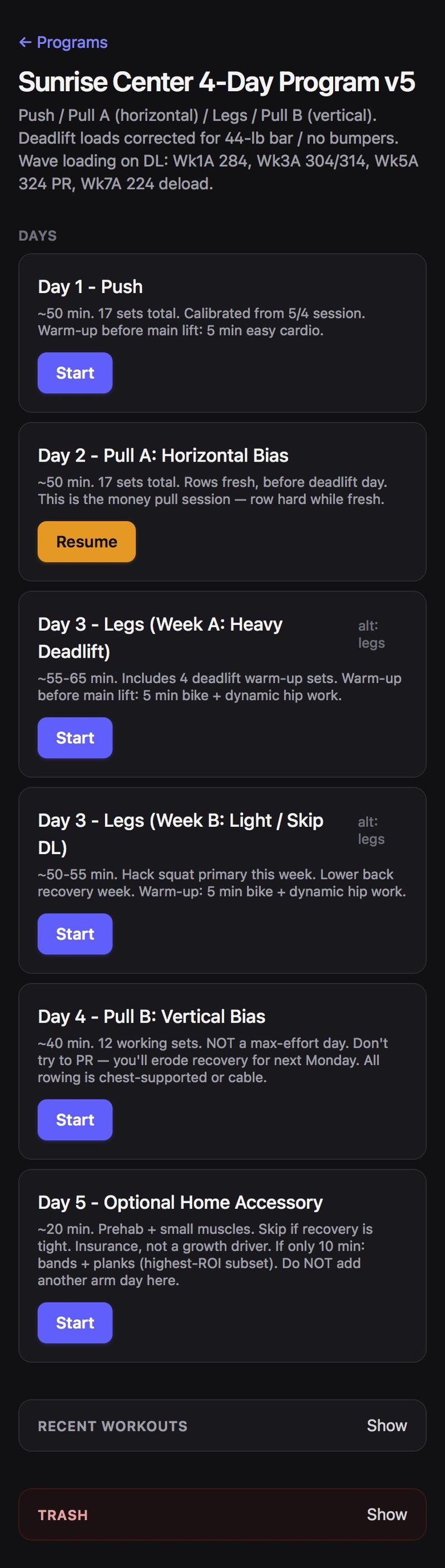
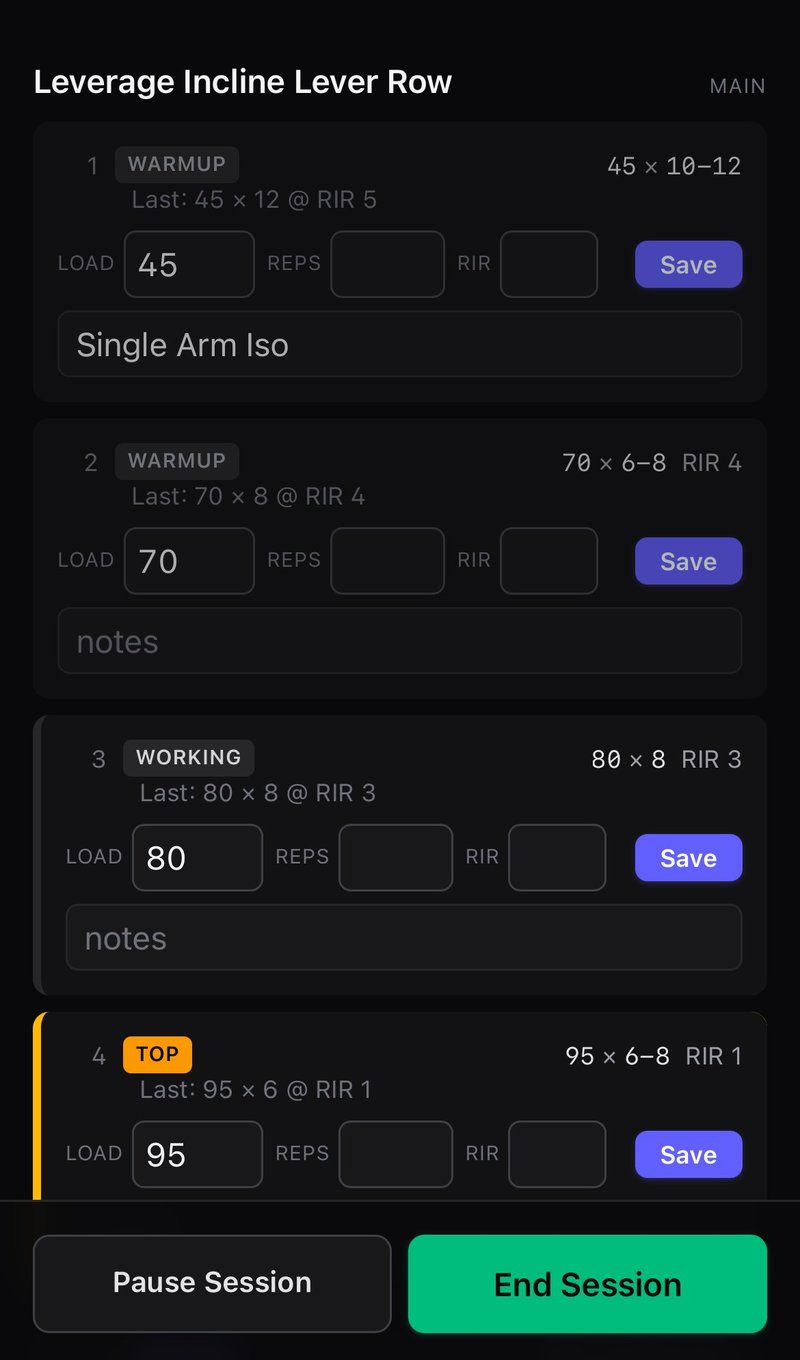
DocLifts is a personal weightlifting log — a phone-at-the-gym tool that prescribes the next set and records what was actually done. Deliberately single-user, self-hosted, no cloud, no auth. The app itself is intentionally modest; it exists as the vehicle for the development process below. Notably, it is not an AI app — LLM features inside the product are explicitly out of scope. The "multi-LLM" story is entirely about how it was built.
It went from planning documents to a production deployment and through its first real production use cycle: a first-day bug surfaced, got fixed in layers, and the next real workout ran cleanly.
The process: many AI tools, one set of written invariants
The central idea: rather than one assistant doing everything ad hoc, several AI tools each do what they're best at, and they stay coherent by reading the same version-controlled documents. Coordination happens through written artifacts, not shared memory — because AI tools don't reliably share memory across sessions or across products, but they can all read a file.
The coordinating artifacts:
- Planning docs (
planning_v2_*.md) — the locked source-of-truth design decisions. The standing instruction to every assistant: when in doubt, re-read these, not your training data. CLAUDE.md— shared operating rules written for any AI coding tool (Claude, Cursor, others), so different assistants don't contradict one another.STATUS.md— a cross-session handoff document: current state, known gaps, recent work. Any agent or human picking up the project reads this first.- A dedicated test-author sub-agent with its own accumulated memory files (infrastructure patterns, recurring bug shapes, a coverage map), so a specialized, repeated task gets better over time.
Division of labor
- Claude (chat) — architecture, design review, code review, drafting documents, catching reasoning gaps. Could read and reason about the code via the repository, but couldn't write to disk.
- Claude Code (on the server) — the executor: wrote files, ran commands, managed the database, deployed. Reads
CLAUDE.mdautomatically on every run. - A cross-model review panel — during design, artifacts were run past several other LLMs (ChatGPT, Gemini, Grok) as independent reviewers.
- The human — direction, decisions, approval, and empirical verification. The required node in the loop.
A typical cycle: design and review in chat → draft the change → hand to Claude Code to write and ship → human approves and verifies on real hardware → reconcile the docs.
What actually made it work — the transferable parts
These are the lessons worth carrying to other AI-assisted projects:
Written invariants beat memory. Lock the decisions in version-controlled docs and have every agent read them. Memory is unreliable across tools and sessions; a committed file is not. This is the single mechanism that kept multiple assistants from drifting apart.
The human is the adjudicator, and verification is empirical. AI proposes; the human decides and tests. Claims were checked, not trusted — "configured" was never treated as "working." Backups weren't just set up, they were restore-tested. A deploy wasn't "done" until it was confirmed on the actual production artifact on the real phone, not a stand-in that happened to be close. When two assistant claims conflicted, a real-world test settled it — including one case where an assistant confidently predicted a bug that testing proved didn't exist, and the prediction was retracted with the mechanism explained.
Independent model review is a real quality mechanism. Running design artifacts past multiple independent models surfaced issues a single model missed. The models showed consistent relative strengths as reviewers across this project — worth tracking if you adopt the practice, though that's a single-project observation, not a benchmark.
Doc-drift is structural, so manage it deliberately. AI-generated handoff docs systematically miss work the human did outside the AI's view. Left alone, the written record quietly diverges from reality. A recurring reconciliation pass — checking what the docs claim against what actually happened — kept the record honest. (One example: an assistant introduced an internally inconsistent date into a doc; it was caught, traced, and corrected rather than papered over.)
Self-correction is part of the loop, not a failure of it. Both the assistants and the human caught and reversed errors mid-stream — a wrong bug prediction, the date error above, an architecture decision made and then re-examined. The process assumes individual outputs will sometimes be wrong and is built to catch them, rather than trusting any single result.
The proof point
This isn't a demo. DocLifts shipped to production and entered daily real use. Day one surfaced a genuine concurrency bug — a double-session-creation race on the "Start" button. It got a layered fix: an idempotent server-side helper, a database-level partial unique index, and a client-side guard — defense at three layers rather than one. The next real workout ran cleanly; a full session logged without a hitch.
That arc — build, ship, hit reality, diagnose, fix in layers, stabilize — is the showcase. The process didn't just produce a greenfield build; it handled the messy post-deployment lifecycle, which is where most of the real work in software actually lives.
Stack (for reference)
Process aside, the app runs on: SvelteKit (Svelte 5, runes) + TypeScript + Vite; PostgreSQL 16 with Drizzle ORM; Zod for validation; Tailwind for the UI. Hosted via @sveltejs/adapter-node as a systemd service, fronted by Tailscale Serve over HTTPS, on an Ubuntu VM (Node 24, pnpm). The full Vitest suite — 120+ and counting — runs against real Postgres in CI, nothing skipped. Daily pg_dump backups with a verified restore path. No auth, no cloud, single-user by design.